
Insider Brief
- Researchers developed a quantum neural network training framework that enabled direct gradient-based optimization on quantum hardware while maintaining performance comparable to strong classical imputation methods on a clinical dataset.
- The approach combines a Butterfly circuit architecture, layer-wise training and a parallelized gradient-estimation technique to substantially reduce the number of quantum circuit evaluations required during training.
- Using IonQ’s Forte Enterprise trapped-ion system, the team demonstrated 16-qubit on-hardware training and 32-qubit hardware inference for a hybrid quantum-classical model applied to clinical data imputation and patient survival prediction.
A team of researchers has developed a quantum neural network training framework that reduces the cost of calculating gradients during training, one of the most significant obstacles in quantum machine learning.
According to the study, posted on the preprint server arXiv, the approach lowers the number of circuit evaluations required for each optimization step from a quantity that scales roughly with the square of the number of qubits to one that scales only logarithmically. The researchers say that reduction enabled direct gradient-based training on IonQ’s Forte Enterprise trapped-ion quantum computer and allowed them to apply the method to a clinically relevant data-imputation task.
The work addresses a longstanding challenge in quantum machine learning, according to the team, which included scientists representing IonQ, Université Paris Cité, CNRS, QC Ware and Quantum Signals. Quantum neural networks, or QNNs, are quantum circuits with adjustable parameters that can be trained in ways analogous to classical neural networks. In theory, they may offer advantages for certain learning tasks. In practice, however, training them on actual quantum hardware has proven difficult because calculating gradients typically requires repeatedly running large numbers of quantum circuits.

The researchers report that this overhead has been one of the main reasons why many quantum machine-learning demonstrations remain confined to simulation or very small hardware experiments.
As discussed below, the framework combined three co-designed ingredient, including a specialized circuit design, a layer-by-layer training strategy and a parallelized gradient-calculation technique.
Tackling a Scaling Problem
Traditional parameter-shift methods, widely used to train quantum circuits, require separate circuit evaluations for individual parameters. As models grow larger, the number of required evaluations increases rapidly.
The new framework seeks to avoid that bottleneck through three design choices.
The first is a circuit architecture called a Butterfly network. Inspired by structures used in fast Fourier transforms, the architecture arranges quantum operations in a pattern that allows information to spread across the system while keeping circuits relatively shallow. According to the study, the design substantially reduces the number of trainable parameters required as systems grow larger.
The second component is a layer-wise training strategy. Rather than training every parameter in the quantum neural network simultaneously, the method trains smaller circuit blocks first and then incrementally adds new layers. Previously trained layers are frozen while new layers are optimized.
The third component is a parallelized version of the parameter-shift rule. Because gates within each Butterfly layer act on different qubit pairs and commute with one another, the researchers can calculate gradients for an entire layer using a constant number of circuit executions rather than evaluating each parameter individually.
Together, these techniques dramatically reduce the number of quantum circuit evaluations required during training.
The researchers report the scaling advantage using several examples. A conventional parameter-shift approach applied to a 128-qubit Butterfly circuit would require 1,792 circuit evaluations for gradient calculations, while their method would require only 28.
Testing on Clinical Records
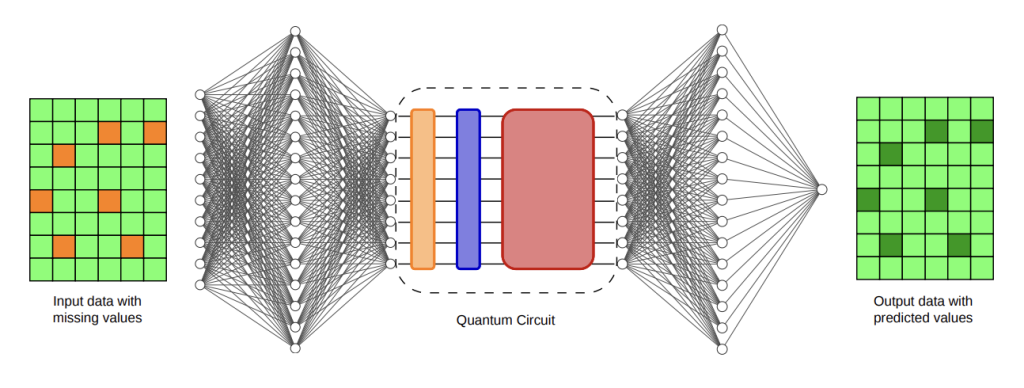
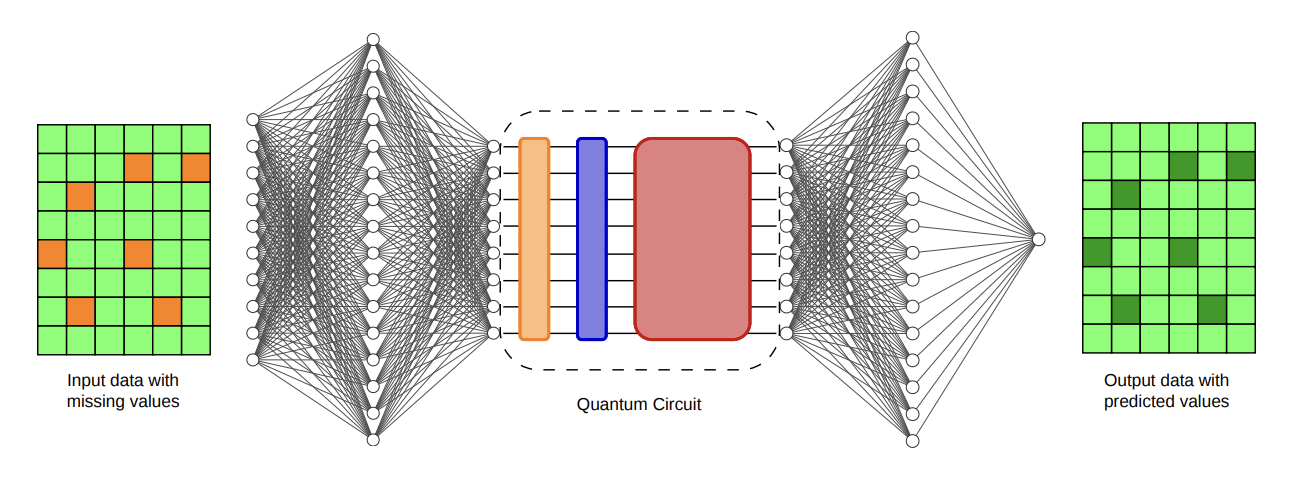
To evaluate the framework, the researchers selected clinical data imputation, a problem outside traditional quantum-computing benchmarks.
Data imputation involves filling in missing entries in datasets. In healthcare records, missing information is common because of inconsistent measurement schedules, sensor failures or incomplete data collection. Accurate imputation can significantly affect downstream predictive models used in healthcare analytics.
The team used the MIMIC-III dataset, a widely studied collection of de-identified intensive-care-unit records. They introduced missing values into the dataset and then compared various methods for reconstructing the missing information.
The benchmark included common statistical techniques such as mean imputation and zero filling, as well as more sophisticated approaches including K-nearest-neighbor imputation, Multiple Imputation by Chained Equations (MICE), MissForest and a neural-network-based Deep MICE model.
The researchers evaluated imputation quality indirectly through predicting patient survival. Performance was measured using area under the receiver operating characteristic curve, or AUC, a standard classification metric in which higher values indicate better predictive performance.
Among the classical methods, Deep MICE produced the strongest average performance, achieving an AUC of 0.7176.
The hybrid quantum-classical model trained on 16 qubits achieved an AUC of 0.7147, while a 32-qubit hybrid model achieved an AUC of 0.7132, placing both within a few thousandths of the leading classical result.
Although the quantum models did not surpass the best classical baseline, they remained within a narrow range of performance and showed lower variability across repeated runs.
According to the researchers, this stability may indicate beneficial inductive biases arising from the structured Butterfly architecture and training protocol.
Training Directly on Quantum Hardware
The study offered an important demonstration of direct training on a commercial quantum computer.
The researchers trained the final layer of a 16-qubit Butterfly quantum neural network on IonQ’s Forte Enterprise trapped-ion system. Earlier stages of the model were trained in simulation and then incorporated into the hardware-trained network.
They compared three scenarios, including ideal simulation, noisy simulation and direct hardware execution.
According to the results, the performance differences among the three training approaches were statistically insignificant. The hardware-trained model achieved results comparable to simulated models while maintaining similar predictive performance.
The researchers report that this as evidence that the logarithmic-scaling training framework is robust enough to operate under current hardware noise levels.
This finding is important because many previous quantum machine-learning demonstrations have relied heavily on simulations rather than actual quantum processors. Hardware noise and long training times have often made direct optimization impractical.
The trapped-ion architecture used by IonQ may have helped. The system provides all-to-all qubit connectivity, allowing the Butterfly circuits to be implemented without extensive compilation overhead.
Extending to 32 Qubits
The study also explored larger system sizes. Because direct 32-qubit training remains computationally demanding, the researchers used matrix product state tensor-network simulations to train larger quantum layers. Matrix product state tensor-network simulations is a computational approach that approximates the behavior of quantum systems by capturing their most important relationships while reducing the amount of information that must be tracked. Inference, however, was executed on IonQ hardware.
The resulting 32-qubit hybrid model performed comparably to a classical neural network with an equivalent hidden-layer width.
The researchers interpret this as evidence that larger quantum circuits produced through their layer-wise framework remain compatible with real hardware and can function without measurable degradation.
Limitations and Future Directions
The work includes several important limitations that point toward future work.
First, the study focuses on a controlled proof-of-concept imputation task rather than a production-scale healthcare workflow. Only one feature column was imputed using the quantum model, while the remaining missing values were handled by classical methods.
The missing-data patterns were also generated using a Missing Completely At Random model. Real-world clinical data often exhibit more complex missingness patterns that may be harder to address.
Finally, the hybrid models matched rather than exceeded the strongest classical baseline. The results therefore demonstrate feasibility and competitiveness rather than a clear quantum advantage.
The researchers also note that larger systems will likely be necessary before any potential performance advantages become evident. Based on comparisons with classical neural-network architectures, they estimate that approximately 128 qubits may be required to match the representational capacity of the strongest classical model used in the study.
Even so, the researchers write that the framework’s significance lies less in current performance numbers and more in enabling scalable on-hardware training.
As quantum hardware continues to improve, the combination of structured circuit architectures, layer-wise optimization and parallel gradient evaluation could allow quantum neural networks to tackle increasingly complex machine-learning problems.
For a deeper, more technical dive, please review the paper on arXiv. It’s important to note that arXiv is a pre-print server, which allows researchers to receive quick feedback on their work. However, it is not — nor is this article, itself — official peer-review publications. Peer-review is an important step in the scientific process to verify results.
The research team included Natansh Mathur of the Institut de Recherche en Informatique Fondamentale (IRIF), a joint research laboratory of the French National Centre for Scientific Research (CNRS) and Université Paris Cité, as well as QC Ware in France. Co-authors Panagiotis Kl. Barkoutsos, Masako Yamada and Martin Roetteler were affiliated with IonQ. The study also included Iordanis Kerenidis, who is affiliated with IRIF, CNRS and Université Paris Cité, and Quantum Signals.