
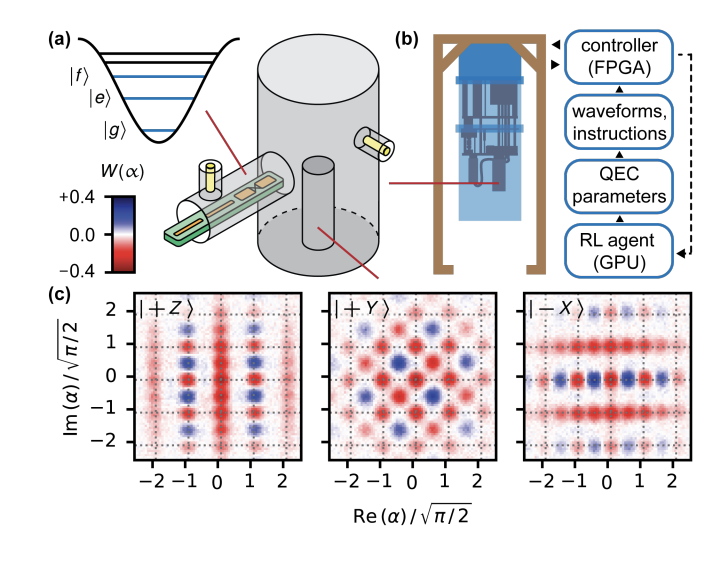

A team of researchers report they were able to create an error-corrected logical qubit with coherence that vastly outperforms current quantum coherence time records. The team used innovations in machine learning and superconducting quantum chip fabrication to create the new system.
The team, which includes researchers from Yale University and Université de Sherbrooke, said that they demonstrated a fully stabilized and error-corrected logical qubit whose quantum coherence is significantly longer than that of all the imperfect quantum components involved in the quantum error correction process, beating the best of them with twice the coherence time.
Because quantum computers are vulnerable to interference from a number of environmental conditions, researchers must find error-correction techniques that can stabilize the computational processes to be used for practical problems. The team says their approach is a huge step in tackling decoherence.
“The purpose of quantum error correction (QEC) is to counteract the natural tendency of a complex system to decohere,” the researchers write. “This cooperative process, which requires participation of multiple quantum and classical components, creates a special type of dissipation that removes the entropy caused by the errors faster than the rate at which these errors corrupt the stored quantum information.”
According to the researchers, the approach is centered on technique to efficiently remove entropy from the system.
“Its core idea is to realize an artificial error-correcting dissipation that removes the entropy from the system in an efficient manner by prioritizing the correction of frequent small errors, while not neglecting rare large errors,” the researchers report.
The researchers, who report their findings in the pre-print server ArXiv, Gottesman-Kitaev-Preskill (GKP) encoding of a logical qubit into grid states of an oscillator.
Reinforcement learning was also used in the experiment, according to the researchers. Reinforcement learning, one of the basic machine learning approaches, uses the maximization of cumulative rewards to guide actions.
“We train the QEC circuit parameters in-situ with reinforcement learning, ensuring their adaptation to the real error channels and control imperfections of our system,” they write.
According to the researchers, there are other areas for improvement in the future.
“In addition, we expect that considerable enhancement can be gained by tailoring the QEC process not only to error channels of the oscillator, but also those of the ancilla,” they write.
For more market insights, check out our latest quantum computing news here.




